مدلهای زبانی بزرگ (LLMs)
ظهور مدلهای زبانی بزرگ (LLMs) نقطه عطفی مهم در تکامل پردازش زبان طبیعی (NLP) محسوب میشود. این مدلها که با مقیاس گسترده و پایههای یادگیری عمیق خود شناخته میشوند، چشمانداز تواناییهای زبانی هوش مصنوعی را دگرگون کردهاند. در مرکز این پیشرفت، مدلهایی مانند نمایشهای رمزگذار دوطرفه از ترنسفورمرها (BERT) و سری ترنسفورمرهای پیشآموزشدیده مولد (GPT) قرار دارند که تاثیر قابلتوجهی بر کاربردهایی مانند ترجمه، تولید محتوا و فراتر از آن داشتهاند.
مدلهای زبانی بزرگ با معماریهای شبکه عصبی عظیم و آموزش گسترده روی مجموعه دادههای عظیم متمایز میشوند. این مدلها عمدتا از معماریهای ترنسفورمر استفاده میکنند که به دلیل پردازش موازی دادهها و مدیریت موثر وابستگیهای بلندمدت در متن شناخته شدهاند. این پیشرفت فناوری، پایه و اساس اثربخشی آنها در درک و تولید زبان است. برت، مدلی پیشگام از گوگل، رویکرد نوینی در آموزش دوطرفه معرفی کرد. با در نظر گرفتن زمینه از هر دو طرف یک کلمه، برت درک ظریفتری از زبان به دست میآورد و عملکرد را در وظایفی مانند تحلیل احساسات و پاسخگویی به سؤالات بهبود بخشید. معماری آن به معیاری در این حوزه تبدیل شده و الهامبخش تغییرات و اقتباسهای متعددی بوده است.
سری GPT، که توسط OpenAI توسعه یافته، رویکرد متفاوتی با مدل آموزش چپ به راست دارد. این مدلها در تولید متن منسجم و مناسب با زمینه برتری دارند و قابلیتهای پیشرفتهای در تکمیل متن و مکالمه نشان میدهند. نسخههای متوالی سری GPT پیشرفتهای مداومی در مقیاس و پیچیدگی نشان دادهاند و توانایی هوش مصنوعی در تولید متنی شبیه به انسان را به طور قابلتوجهی ارتقا دادهاند.
در کاربردهای عملی، مدلهای زبانی بزرگ مشارکتهای قابلتوجهی داشتهاند. در ترجمه ماشینی، آنها روان بودن و دقت بیشتری ارائه میدهند و از روشهای قبلی پیشی میگیرند. در تولید محتوا، این مدلها قادر به تولید متون باکیفیت برای روزنامهنگاری، نوشتن خلاق و محتوای وب هستند که اغلب با متون نوشتهشده توسط انسان قابلمقایسه است.
علاوه بر این، مدلهای زبانی بزرگ در تحلیل احساسات، خلاصهسازی اسناد و سیستمهای پاسخگویی خودکار به پرسشها کاربرد دارند. همچنین، این مدلها به طور فزایندهای در زمینههای تخصصی مانند تحلیل متون حقوقی و پزشکی استفاده میشوند، جایی که توانایی آنها در پردازش و تفسیر زبان پیچیده ضروری است. به بیان دقیقتر، این مدلها با بهبود تعامل انسان و کامپیوتر، پیچیدگی و آگاهی زمینهای چتباتها و دستیارهای مجازی را ارتقا میدهند. در حقیقت، توسعه مدلهای زبانی بزرگ نه تنها وضعیت پردازش زبان طبیعی را ارتقا داده، بلکه دامنه و عمق کاربردهایی که هوش مصنوعی میتواند به طور مؤثر زبان انسانی را پردازش و تولید کند، گسترش داده است.
وضعیت کنونی و جهتگیریهای آینده
وضعیت کنونی پردازش زبان طبیعی و مدلهای زبانی بزرگ با پیشرفت سریع و ادغام فزاینده در کاربردهای متنوع مشخص میشود. پردازش زبان طبیعی، با پشتیبانی مدلهای زبانی بزرگ، به سطوح بیسابقهای در درک و تولید زبان دست یافته و پیشرفتهای قابلتوجهی در وظایفی مانند ترجمه ماشینی، خلق محتوا و هوش مصنوعی مکالمهای داشته است.
مدلهای زبانی بزرگ، مانند سری GPT و BERT، پیشگام این پیشرفتها هستند. این مدلها که روی مجموعه دادههای گسترده آموزش دیدهاند و از معماریهای پیچیده شبکه عصبی بهره میبرند، توانایی قابلتوجهی در درک و تولید متنی شبیه به انسان نشان دادهاند. آنها در بهبود دقت ترجمه ماشینی، ایجاد چتباتهای آگاهتر از زمینه و تولید محتوای نوشتاری منسجم و متنوع از نظر سبک نقش کلیدی داشتهاند.
با نگاه به آینده، انتظار میرود این حوزه شاهد رشد مداوم در پیچیدگی مدلها و تنوع کاربردها باشد. البته، روندهای نوظهور شامل ادغام مدلهای چندوجهی است که قادر به پردازش و ارتباط دادهها از منابع مختلف مانند متن، تصاویر و صدا هستند. همچنین تاکید فزایندهای بر توسعه مدلهای کارآمدتر و پایدارتر از نظر زیستمحیطی وجود دارد، زیرا مدلهای زبانی بزرگ کنونی به منابع محاسباتی قابلتوجهی نیاز دارند.
پیشرفتهایی در درک و تولید جنبههای ظریفتر زبان، مانند طنز، کنایه و زمینههای فرهنگی، نیز پیشبینی میشود. این پیشرفت، کاربرد مدلها را در محیطهای کلان و متنوع فرهنگی افزایش خواهد داد. علاوه بر این، تلاشهایی برای بهبود توانایی مدلها در مدیریت زبانهای با منابع کم در جریان است تا فناوریهای پردازش زبان طبیعی به طیف وسیعتری از زمینههای زبانی گسترش یابد. با این حال، استقرار مدلهای زبانی بزرگ هزینهها و چالشهای قابلتوجهی به همراه دارد. منابع محاسباتی مورد نیاز برای آموزش و اجرای این مدلها قابلتوجه است و هزینههای مالی و زیستمحیطی بالایی را به دنبال دارد. رسیدگی به این هزینهها برای دسترسپذیرتر و پایدارتر کردن فناوریهای پردازش زبان طبیعی حیاتی است.
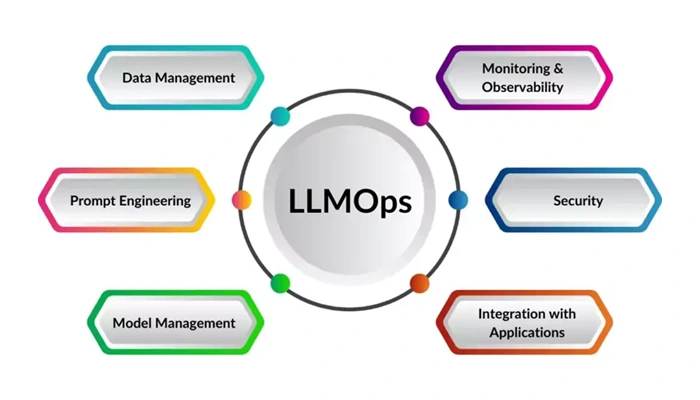
علاوه بر این، ملاحظات اخلاقی و عدالت در آموزش و خروجیهای مدل به طور فزایندهای در کانون توجه قرار گرفتهاند. اطمینان از اینکه مدلهای زبانی بزرگ از تعصبات خالی باشند و استفاده از آنها به استانداردهای حریم خصوصی و اخلاقی احترام بگذارد، نگرانی رو به رشدی است و حوزهای برای تحقیق و توسعه فعال محسوب میشود. اکنون، بیایید به الزامات عملیاتی مدلهای زبانی بزرگ از منظر LLMOps و تفاوت آنها با عملیات یادگیری ماشین (MLOps) بپردازیم… اما اینکار را در بخش بعدی این مطلب انجام خواهیم داد.